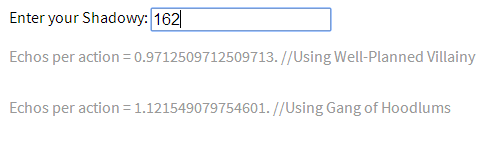
[quote=dov]
Is there a more efficient way to go about this as a grinding method with an expected return of 170-180 ppa?[/quote]
The most efficient way to go about similar challenges is usually to do them as soon as possible, even though it means lower than 100% success rate. The linear success rate increase WRT quadratic CP needed increase just tends to work like that in this game (and the concrete numbers set for the challenges).
In this case, failure costs 5 cp investigating, so you usually need 2 actions worth of university (at ~50 clues gained each, too!) to get back to where you can attempt again.
Chance of success at Nth attempt: P[N] = 0.3**(N-1) * 0.7
Profit when succeeding at Nth attempt: x[N] = 540 + 5*100 + (N-1)*200=840+200N
Action cost when succeeding at Nth attempt: a[N] = 5+(N-1)*3+1=3+3N
Assuming that anything past M attempts is a fail (you just give up, because the potential profit from 540 pence/(3+3M actions) multiplied by P[M] is so small that it doesn’t meaningfully affect the expected profit estimate), you have
E(ppa)=(sum(P[N]*x[N], N=1…M) + AA)/(sum(P[N]*a[N], N=1…M) + BB) // I am taking a huge pool of actions here, and distributing various instances of “succeeded at N-th attempt” between these actions proportionately, scaling to the simplest pool size that came to mind (I could also do "out of 1000000 actions, how many are part of success-at-1? how many are part of success-at-2?, etc …, then divide by 1000000)
and, of course, the real E(ppa)=limit(above, for M->infinity)
BB= sum(P[N]a[M], N=(M+1)…inf represents all actions lost to “failed M attempts, reset to zero and tried again”
with the corresponding profit from university grind being
AA=sum(P[N](500+200*(M-1)), …), because each fail except the last is followed by two actions grinding.
The trick here is that M doesn’t depend on N and Q=sum(P[N], N=(M+1)…inf) = 1-sum(P[N], N=1…M) is easily computable, so:
BB=Qa[M], AA=Q(200M+300)
I put this in a simple script to print values for a few low values of M, and see that the estimate quickly raises from 146 to around 155 ppa, and stays there up to M=990 (e(ppa)=154.5098039…). Higher M causes the script to fail on a recursion depth excess.
That’s not bad, but it isn’t broken. Affair of the box on the side that gives correspondence plaques is 157.6923…ppa, so … no reason to keep university open infinitely here.
(it’s actually slightly better, because not all failures cost 2 actions, but that doesn’t matter until attempt #5, which means only 0.81% of all “runs” are improved by it, and such runs are also already so long that success doesn’t improve your ppa much above the baseline from just grinding investigation; it will not be good enough to overcome AotB)